
Development of the SUS
In 1986, John Brooke developed a short questionnaire intended to measure the perceived usability of various computer systems. Simply a “quick and dirty” scale for usability testing, Brooke made the questionnaire freely available to various colleagues and “anybody else who might find it useful” (Brooke, 2013). Little did he know when he made it the System Usability Scale (SUS) would become one of the most widely used questionnaires in UX, used in nearly 5,000 studies, and cited in over 1,200 scholastic publications (Google Scholar; Brooke, 2013).
One of the reasons for its widespread use is that the SUS is an incredibly simple and quick survey to administer. It’s so simple, in fact, it only has 10 Likert-type questions. Each question is rated on an agreement scale – also known as a Likert scale – between “1” and “5”. A rating of “1” indicates “strong disagreement”, whereas a rating of “5” corresponds with “strong agreement”.
The System Usability Scale (SUS)
1. I think that I would like to use this system frequently.
2. I found the system unnecessarily complex.
3. I thought the system was easy to use.
4. I think that I would need the support of a technical person to be able to use this system.
5. I found the various functions in this system were well integrated.
6. I thought there was too much inconsistency in this system.
7. I would imagine that most people would learn to use this system very quickly.
8. I found the system very cumbersome to use.
9. I felt very confident using the system.
10. I needed to learn a lot of things before I could get going with this system.
It’s easy to see the draw of the SUS: a free measurement tool that allows comparisons between systems and from one benchmark to another. What’s more, the questions never change from system to system. It doesn’t matter if we’re dealing with a luxury vehicle infotainment system, an online shopping portal, or the interface of an electronic medical record (EMR).
However, the SUS does have its fair share of drawbacks. There are important details of the SUS, its depth of focus, and what its results inform that can be overlooked – especially among those that are new to using it.
With these strengths and limitations in mind, we have compiled a list of “pros” and “cons”. Some strengths carry more weight than others – and, the same can be said for the weaknesses. One thing to keep in mind when you read through this list is that context matters, and ultimately, how impactful each “pro” and “con” can be.
The Pros
The SUS has a high Cronbach’s Alpha
The validity has been tested time and again for the SUS. It can help you distinguish between usable and unusable systems, and it is also consistent with other usability measures (Sauro, 2011). In a meta-analysis looking at a decade’s worth of SUS findings, Bangor, Kortum, and Miller (2008, 2009) reviewed over 3,500 SUS results and found a close correlation between other subjective ratings of usability and the SUS.
Similarly, in a 2011 article for UXPAMagazine.com discussing his 2009 study, Jeff Sauro briefly outlines the SUS’ Cronbach’s Alpha. If you aren’t familiar with it, Cronbach’s Alpha is a coefficient of statistical reliability/consistency, ranging from “0” to “1”. The closer the coefficient is to “1” the more reliable and consistent your items are at retesting the same metric(s). According to Sauro, in the “most comprehensive examination” thus far, the Cronbach’s Alpha was .92 (Sauro, 2011; Lewis & Sauro, 2009).
Additionally, these strong internal consistency numbers seem to hold true even for small sample sizes (Tullis & Stetson, 2004). For instance, Tullis & Stetson (2004) determined that even with twelve participants, the SUS reached the same results as a larger sample size in at least 90% of cases examined. Although the SUS was meant to be a “quick and dirty” measure of perceived usability, its high degree of consistency makes it quite valuable.

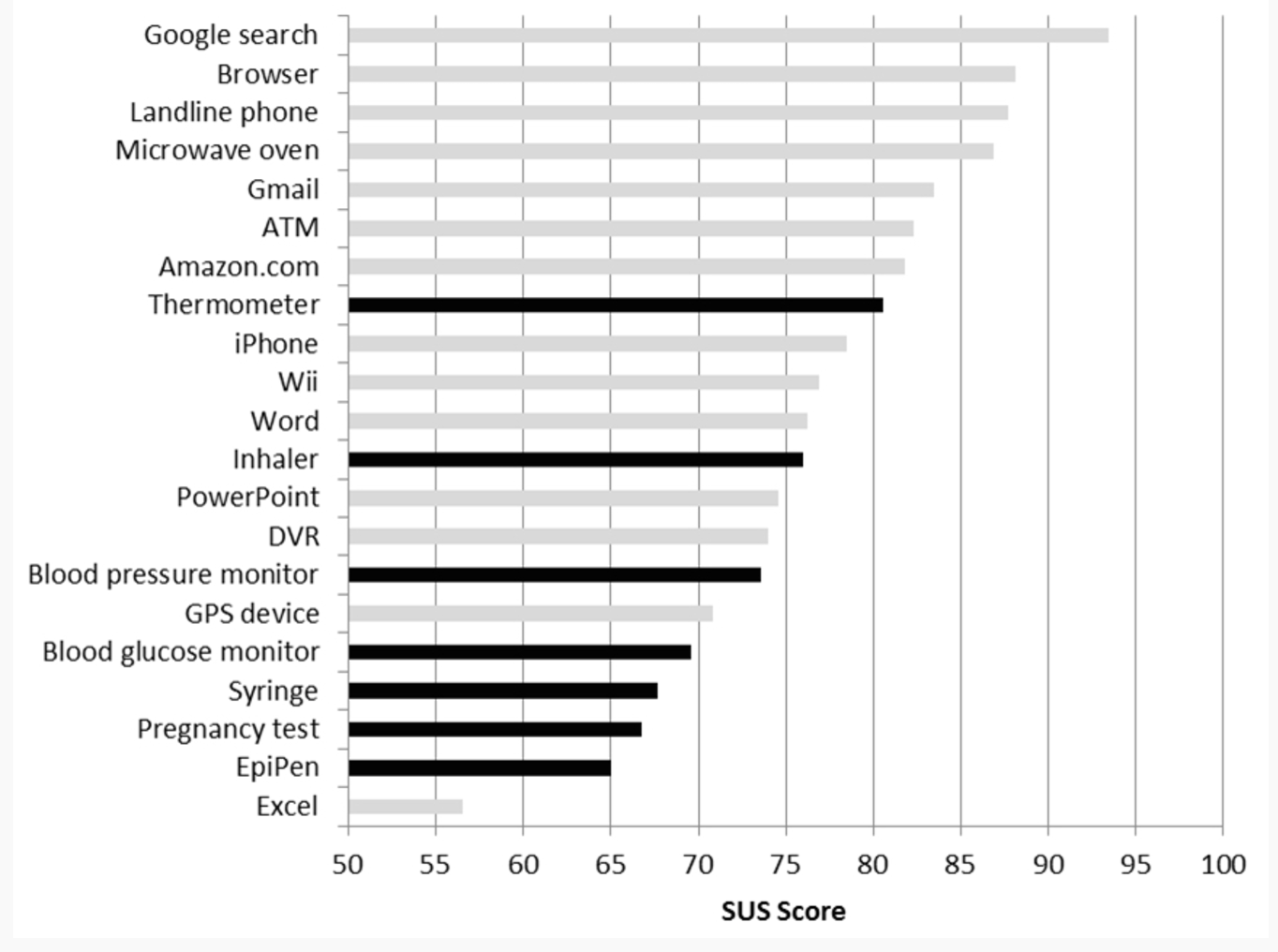
The SUS is also flexible. In a recent article for Measuring U, Jeff Sauro says he has seen “SUS data for desktop applications, printers, cell-phones, Interactive-Voice Response systems and more recently on websites and web applications” (Sauro, 2010).
Applicable to a wide range of technologies, systems, and products.
The fact that the SUS is so versatile is actually a pretty big deal. Together with its wide applicability, the quickness and ease associated with the SUS make it an exceptionally popular tool, and its high usage further boosts the scale’s value. Because so many people know about it, the SUS is not only familiar, it also means that the scores can be compared with one another, even if the tested products are completely unrelated. For example, you could evaluate a car infotainment system and compare its SUS score to an online TV streaming service – (though I’m not sure why you’d want to).
Another implication of the SUS’ versatility is the additional confidence it brings to the researcher. While each situation differs and must be separately evaluated for unique research needs, the SUS is very likely going to serve your new usability test well. It doesn’t matter if you’re starting a website, a new software program, or building an operating station for construction equipment. The SUS is a great place to start when looking for subjective usability measures and devising a new measure based on the SUS or using it as-is are credible options.
The SUS is highly accessible
The SUS is free. Not “free” as in, “sign up for our monthly newsletter and we’ll send you some swag” – “free” as in Google it and all the questions are listed out right there. It’s super easy to find and almost any article about the System Usability Scale will include the scale itself. In a world where everything costs something, that’s pretty handy! In all seriousness, there are always budget and resource considerations when conducting usability research. The SUS is a free and robust tool for gathering subjective data from participants; the only costs associated with the SUS are time and effort.
Additionally, the SUS can be used in multiple languages. While translated questionnaires often introduce major problems with internal reliability, the SUS seems to hold up (Sauro, 2011). There is literature discussing difficulties with non-native English speakers (Brooke, 2013; Finstad, 2006) but other researchers were able to successfully alleviate those problems with a few simple word swaps (Bangor, Kortum, & Miller, 2008; Lewis & Sauro, 2009).
The Cons
The SUS is a subjective measure of perceived usability

For the most part, there is absolutely nothing wrong with the above statement. After all, the SUS was originally designed with these qualifying adjectives in mind (Brooke, 2013). The problem is that some lose sight of what the SUS is intended to measure (and the implications that can be drawn from the results).
The common issue here is that the SUS is mistaken as an objective measure of a system’s usability. This is not true. Again, it is a measure of the perceived usability of a system. While the difference between perceived (i.e., subjective) and actual (i.e., objective) usability may seem trivial to some, the difference is meaningful.
The construct of perceived usability is flawed in itself. Despite our confidence, humans are actually quite inconsistent and prone to bias while rating their own usability experience after interacting with a system. For example, there is often a sizable discrepancy between how well someone thinks they did in a task and how well they actually did. What the participant experiences as well as how successful the interaction is can differ from one another quite a bit. The SUS only measures the participant’s version of this interaction.
Importantly though, their version of the interaction – as pleasantly distorted or torturously honest as it may be – does ultimately define how they remember and perceive the system overall. In turn, this strongly influences the likelihood that they will or will not invest resources (e.g., time, attention, loyalty, money) into the company’s products.
The SUS should not be your only method.
The System Usability Scale should be implemented alongside other, more objective measures to complement the perceived usability findings. SUS scores by themselves carry only one part of the entire usability experience.
As a construct, Brooke adopted the definition of usability as the culmination of three major components: Effectiveness, Efficiency, and Satisfaction (Brooke, 2013). Effectiveness and Efficiency are the two objective components at play here (i.e., pass vs. fail, time on task). Satisfaction, of course, is the subjective component that deals with an individual’s confidence, comfort (physiological and cognitive), and emotional experience (Brooke, 2013).
John Brooke wrote that back in the 80s, task completion, completion speed, and task understanding adequately evaluated Effectiveness and Efficiency for a system, where as Satisfaction was left out of a large portion of usability studies. Indeed, the SUS was Brooke’s answer to those needs, to incorporate measurement of the third component into usability as a whole “in addition to the objective measures” (Brooke, 2013).

And so we return to the main message: the SUS was never meant to be used on its own. It provides a subjective measure of a user’s satisfaction with a system, and while not meaningless, is much more powerful when used with other tools collectively.
In reality, this detail is not a con, per se. People who use the SUS just need to keep this in mind while planning a study and analyzing its results. The System Usability Model is not a catch-all, end-all measure, but simply an important part of a larger whole.
The SUS is not a diagnostic tool.
The SUS provides one score that identifies a system’s perceived usability score, but does not identify anything further than that.
Let’s say your system received a SUS score of 70, average when it comes to SUS. If your product is later in the development cycle, you expect it to do much better — maybe, 80. What can you do to improve your score?
Well, there are tons of great research methods that can help you answer that question, but the SUS is not one of them. Task completion rates and time on task results are going to be more helpful when trying to identify specific problem areas. The SUS results *should* simply corroborate these objective measures. That is to say, tasks that take exceptionally long periods of time to complete, or require too much effort to complete should be accompanied by a lower SUS score. This isn’t always the case — remember, people aren’t the best at evaluating their performance.
There may also be some limitations when comparing multiple SUS scores. In an examination of the System Usability Scale’s validity (smaller in scale to Bangor, Kortum, & Miller 2008, but same idea), Peres, Pham, & Phillips (2013) suggested that comparing SUS scores can only occur ordinally. In other words, while SUS scores may indicate that one system is perceived as more usable than another, those comparisons would not be able to conclude how much more usable the system was.
The same is true when you test your product from one iteration to the next. The main thing you want to see is that your SUS score is increasing after each iteration. If it’s the same as before — or lower — then, you know that what you changed between then and now did not meaningfully influence your users’ perceived usability of the product.
Moving Forward
Like any research method, survey, or questionnaire, the SUS has its share of strengths and weaknesses. As researchers and designers in UX and Human Factors, it’s critical to know everything you possibly can about a measure such as SUS before implementing it in a study. Particularly when you have teammates or clients with less experience working with this questionnaire, laying all the cards on the table will help your team know what to expect when using SUS in a study.
For more resources on Medical Device Human Factors please check out our blog and YouTube channel.
References:
Bangor, A., Kortum, P. T., & Miller, J. T. (2008). An empirical evaluation of the system usability scale. Intl. Journal of Human–Computer Interaction, 24(6), 574-594.
Bangor, A., Kortum, P., & Miller, J. (2009). Determining what individual SUS scores mean: Adding an adjective rating scale. Journal of usability studies, 4(3), 114-123.
Brooke, J. (1996). SUS-A quick and dirty usability scale. Usability evaluation in industry, 189(194), 4-7.
Brooke, J. (2013). SUS: a retrospective. Journal of usability studies, 8(2), 29-40.
Finstad, K. (2006). The system usability scale and non-native english speakers. Journal of usability studies, 1(4), 185-188.
Kortum, P., & Peres, S. C. (2015). Evaluation of home health care devices: Remote usability assessment. JMIR human factors, 2(1).
Lewis, J., & Sauro, J. (2009). The factor structure of the system usability scale. Human centered design, 94-103.
Peres, S. C., Pham, T., & Phillips, R. (2013, September). Validation of the System Usability Scale (SUS) SUS in the Wild. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting (Vol. 57, No. 1, pp. 192-196). Sage CA: Los Angeles, CA: SAGE Publications.
Sauro, J. (2010). Can you use the SUS for websites? Retrieved from https://measuringu.com/sus-websites/
Sauro, J. (2011). Measuring Usability with the System Usability Scale (SUS). Retrieved from https://measuringu.com/sus/
Sauro, J. (2011). SUStisfied? Little-Known System Usability Scale Facts. User Experience Magazine, 10(3).
Retrieved from http://uxpamagazine.org/sustified/
System Usability Scale. Retrieved from https://www.usability.gov/how-to-and-tools/method s/system-usability-scale.html



